推荐算法:MCLP论文解读
论文:Going Where, by Whom, and at What Time: Next Location Prediction Considering User Preference and Temporal Regularity
作者:Tianao Sun, Ke Fu, Weiming Huang, Kai Zhao, Yongshun Gong, Meng Chen (山东大学、南洋理工大学、佐治亚州立大学)
发表:KDD 2024
阅读时长:约 15 分钟
难度:⭐⭐⭐ (需要轨迹挖掘、Transformer 基础)
前置知识:Transformer 架构、LDA 主题模型、人类移动性建模
本文针对下一地点预测(Next Location Prediction)中用户偏好建模浅层化和时间规律利用不足的问题,提出了 MCLP 模型。核心创新在于将用户偏好(通过 LDA 挖掘)和下一时刻到达时间(通过注意力机制估计)显式作为上下文信息注入 Transformer 预测框架,在两个真实数据集上显著提升了预测精度。
论文概述
问题:现有的移动性预测模型往往将用户偏好简化为随机初始化的向量,且未能充分利用“到达时间”这一关键决定因素,或者仅将其视为辅助任务。
方案:提出多上下文感知位置预测模型(MCLP),通过显式建模用户偏好和预计到达时间作为核心上下文。
贡献:
- 提出一种联合建模用户偏好、时间规律和序列模式的新范式。
- 利用概率主题模型(LDA)提取用户地点偏好作为先验知识。
- 设计基于多头注意力机制的到达时间估计器,为位置预测提供动态时间上下文。
- 在交通摄像头和手机信令两个真实数据集上证明了 MCLP 的优越性。
背景与动机
人类移动性具有高度的规律性,但也存在随机性。下一地点的选择往往受限于“谁在走”和“什么时候走”:
- 用户偏好(By Whom):不同用户有不同的生活习惯(如购物达人 vs. 学习爱好者)。传统的 Embedding 方法往往从零开始学习,难以捕捉轨迹中蕴含的显式偏好。
- 时间规律(At What Time):时间是地点的强约束(如中午去餐厅,晚上回家)。以往研究要么忽略到达时间,要么将其作为次要的辅助任务,未意识到预测时间比预测地点容易得多,且时间可以作为预测地点的有力证据。
论文通过移动熵(Mobility Entropy)分析证明,引入时间上下文后,用户移动模式的熵值显著降低,这意味着预测的可行性和准确性理论上会更高。
核心方法
MCLP 的整体架构由三个核心组件组成:用户偏好挖掘、到达时间估计和序列模式挖掘。
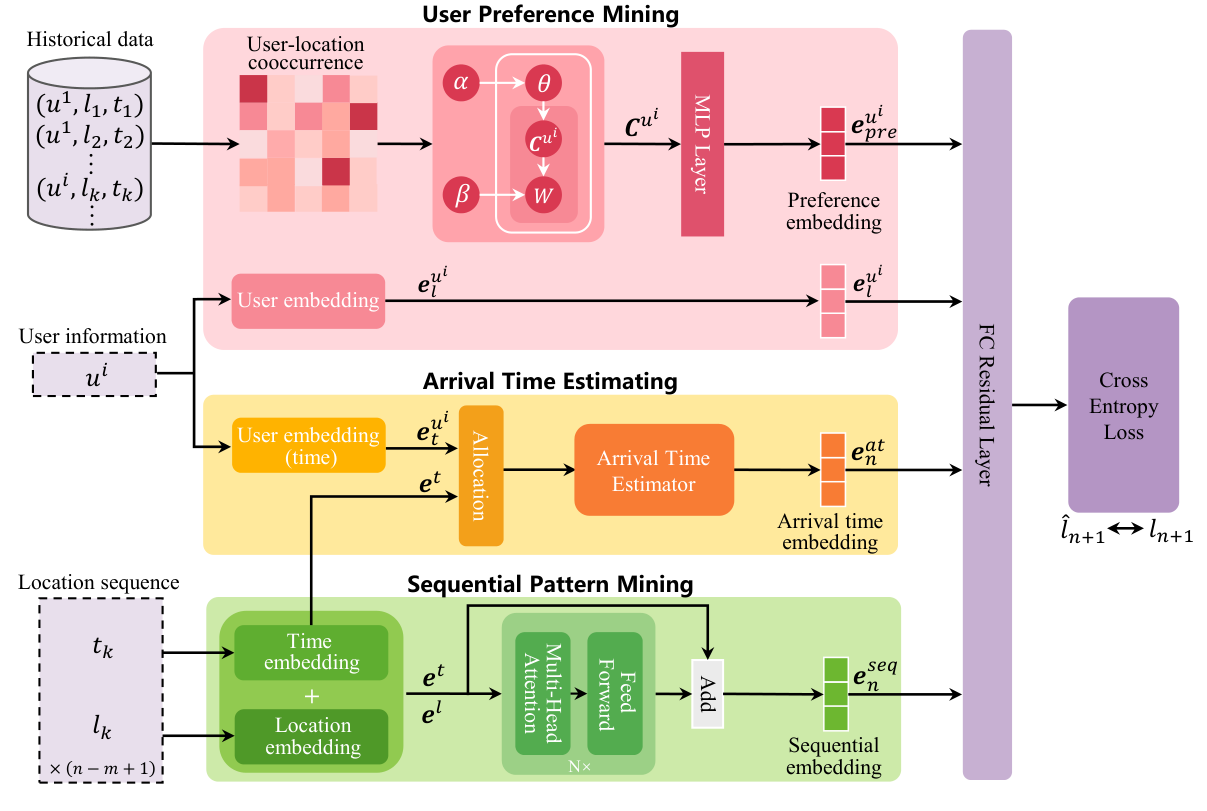
1. 用户偏好挖掘 (User Preference Mining)
为了注入先验知识,模型将用户轨迹视为“文档”,地点视为“单词”,利用 LDA (Latent Dirichlet Allocation) 模型生成用户-主题分布。
- 输入:用户-地点共现矩阵。
- 输出:用户偏好向量
。 - 处理:通过一个带有残差连接和 LayerNorm 的 MLP 进一步提升语义表达,得到偏好嵌入
。
2. 到达时间估计 (Arrival Time Estimating)
这是本文的亮点之一。模型不再直接预测下一地点,而是先估计“什么时候到达”。
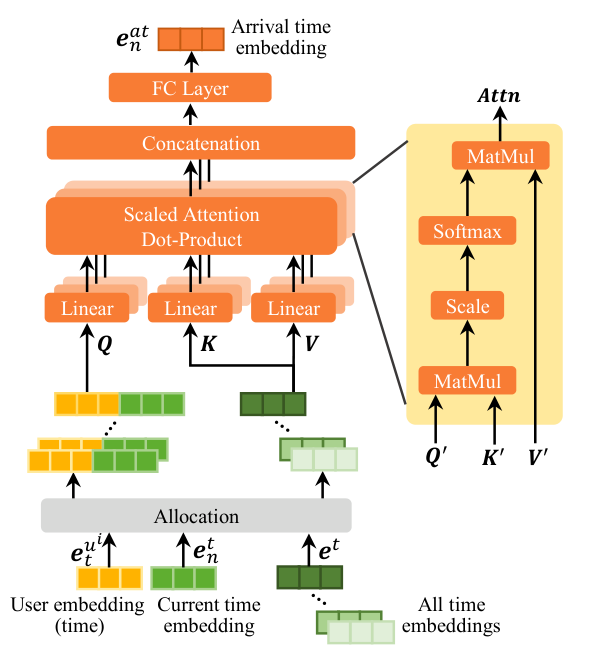
- 输入:用户时间嵌入
(识别个性化时间偏好)、当前时间嵌入 和所有候选时段嵌入。 - 核心机制:使用多头注意力机制(MHSA),以当前时间和用户个性化时间为 Query,所有候选时段为 Key/Value,计算加权聚合的到达时间嵌入
。 - 设计逻辑:这种方法比单一时段预测更具鲁棒性,能捕获用户在特定时间段内的行为概率分布。
3. 序列模式挖掘 (Sequential Pattern Mining)
使用 Transformer 编码器捕捉用户地点的长短期依赖关系。
- 输入序列:地点和时间的嵌入序列
。 - 输出:序列上下文向量
。 - 增强:通过残差式连接加入当前位置和时间信息,生成最终的序列嵌入
。
4. 最终预测
将上述四个嵌入向量拼接,通过全连接残差层进行 Softmax 分类:
实验分析
主实验结果
模型在 Traffic Camera 和 Mobile Phone 两个数据集上均取得了 SOTA 性能。
| 方法 | Traffic Camera (MRR) | Mobile Phone (MRR) |
|---|---|---|
| DeepMove | 46.08 | 49.11 |
| Flashback | 47.33 | 50.22 |
| GETNext | 47.15 | 49.89 |
| MCLP | 51.46 | 51.81 |
关键结论:相比于将到达时间作为辅助任务的模型(如 GETNext),MCLP 这种显式将其作为上下文的方法表现更好,证明了时间规律对地点预测的直接决定作用。
消融实验
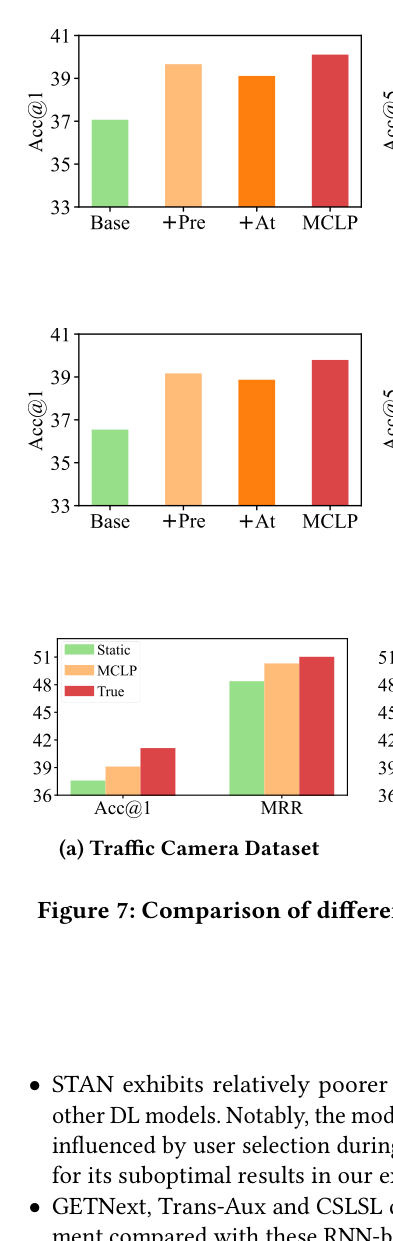
实验证明,+Pre(用户偏好)和 +At(到达时间)组件均能独立提升模型性能,而两者结合时效果达到最优。
深度理解问答
Q1: 为什么使用 LDA 提取偏好比直接让模型学习 Embedding 更好?
直接学习的 Embedding(如传统模型中的 UserID Embedding)本质上是在学习一个 ID 的唯一表示,它需要大量的训练数据才能逐渐“悟”出用户的偏好。而 LDA 是基于全局统计规律的先验知识,它能直接识别出“这个用户经常去商场和电影院”这类高层语义,为模型提供了一个极佳的搜索起点,缓解了数据稀疏问题。
Q2: 到达时间估计器中,为什么不直接预测一个具体的时间点?
人类的行为在时间上具有一定的“模糊性”。例如,你可能在 18:00 到 19:00 之间的任何时间去吃晚饭。如果模型只预测一个点,容错率极低。MCLP 通过注意力机制生成一个聚合的时间嵌入,本质上是捕获了用户在未来多个可能时段的概率分布,这种“软预测”作为上下文注入到地点预测中,比一个“硬预测”的数值包含更丰富的信息。
Q3: 模型在处理超长轨迹时表现如何?
MCLP 采用了 Transformer 架构,理论上具有捕捉长距离依赖的能力。同时,通过 LDA 提取的全局偏好嵌入实际上起到了一种“长期记忆”的作用,弥补了 Transformer 在处理极长序列时的计算瓶颈或信息遗忘。
总结与思考
核心贡献
- 范式转变:将到达时间从“预测目标”转变为“预测依据”,利用了时间规律的强预测性。
- 知识注入:通过主题模型引入先验偏好,提升了冷启动或稀疏数据下的表现。
局限性
- 计算开销:LDA 预处理和 Transformer 架构在超大规模实时系统中可能面临推理延迟挑战。
- 动态偏好:LDA 提取的是静态全局偏好,对于用户短期内兴趣的剧烈转变(如出差、旅游)捕捉可能不够敏锐。
适用场景
- 智慧城市交通规划:利用摄像头数据预测车辆去向。
- 个性化 LBS 推荐:根据用户长期习惯和当前时间精准推送服务。