Kafka的理解?
Kafka 本质上是一个消息队列中间件,经常在高并发的场景下我们会见到它,那顾名思义它就是面向于高并发的场景。下面我们来简单了解一下它吧~
kafka有几个关键的概念
既然是消息队列,那么一定包含生产者和消费者:
每个生产者生产的消息都会属于一个topic,同一个topic的消息们会按照策略被分到不同的分区(partion)中,为了高可用,每个topic的多个partion都会有副本,将会存到不同的broker上,broker可以看作是服务器,它可以有多个话题的partion,可以从下图中看出他们的关系:
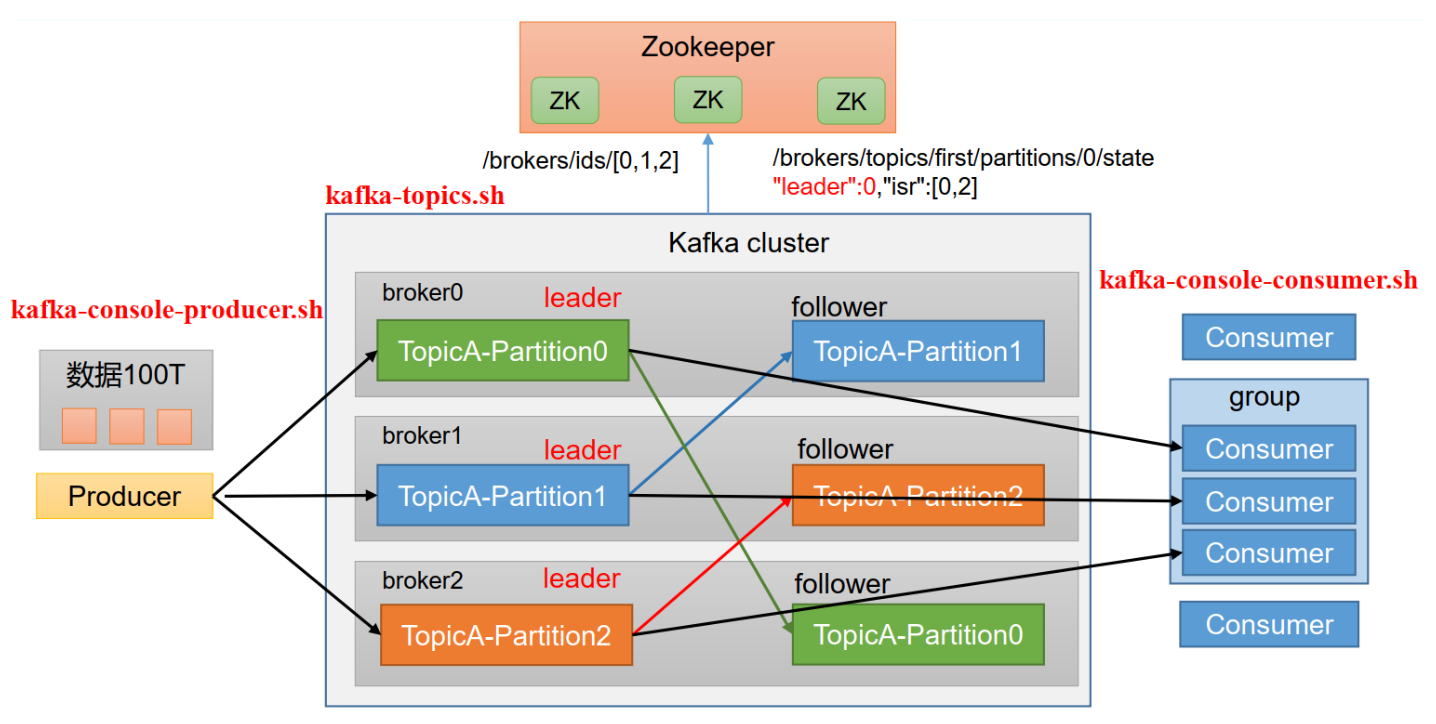
为什么要这么设计?
首先多副本可以保证改可用性,即使当前brocker挂了,也会在其他brocker里面找到对应的副本恢复,并将副本所在的节点转换成主节点。
其次topic的消息的存放分到多个partion,实现负载均衡,分摊单个服务器的存储压力。
还有意思的是消费者这边的设计。
为了增大吞吐量,引入消费者组,消费者组内成员不能消费同一条消息,消费者组可以订阅多个topic,;
为了使多个消费者可以消费同一条消息,这里针对消费者组在分区引入各个消费组的偏移量,这样即使消费组的成员消费了,也不会影响其他消费组的消费者成员消费(解决重复消费的问题)即:
同一消费者组内 “分工消费”(1 个分区仅被 1 个消费者消费),本质是通过 “分区重平衡(Rebalance)” 机制,让组内消费者公平分配 Topic 的分区,确保 “分区 - 消费者” 的唯一映射。
不同消费者组 “重复消费” 同一 Topic,核心是 “消费进度(Offset)按组隔离”,每个组独立记录自己的消费位置,互不干扰。
简单总结:
- 对内(同组):“分任务,提效率”(不重复、高吞吐)。
- 对外(跨组):“多副本,保灵活”(可重复、多场景)。
Kafka 是怎么解决消费失败后可重复消费的?
核心本质是:通过消费者自主管理偏移量(Offset)。当消费失败时,消费者不提交当前偏移量,下次消费会从上次提交的偏移量重新开始,从而实现消息重消费。消息是否保留由过期时间等规则决定,但重复消费的关键是偏移量未提交,而非消息未删除。
另外高频的kafka考点是,如何保证顺序消费?
对于生产者,每条消息是追加写的都有分配的递增序号;
对于消费者来说,通过偏移量标识已经消费的消息偏移量。
简单总结一下即为:
写入时有序:分区的日志结构(追加写)决定了消息在分区内天然有序,Offset 是有序性的 “序号标识”。
消费时有序:1)消费者必须按 Offset 递增顺序读取;2)消费者组机制确保一个分区仅被一个消费者消费,避免多消费者并发处理导致的乱序。
Kafka 如何高效管理海量数据,面对 TB 级数据,它如何做到 “快速写入 + 快速查询”?
Kafka 记录消息时,会按分区 + Offset 顺序将消息追加到分段的日志文件(.log)中(顺序写入避免随机 IO,保证快速写入);同时,会为每个日志分段生成对应的索引文件(.index),记录 “消息 Offset 与它在.log 文件中的物理位置(如字节偏移量)” 的映射关系。
后续查询时,无需扫描全量日志,只需先通过索引文件快速定位到目标消息所在的分段和具体物理位置,再直接读取.log 文件中的数据,从而实现海量数据下的快速查找。
关于kafka集群的管理,原来使用的Zookeeper是怎么感知kafka集群的变化的?
核心是 “节点主动注册 + 连接断连感知 + 变化通知”:
- Kafka 的 Broker、消费者等节点启动时,会主动在 Zookeeper 上创建节点( Broker 对应临时节点),把自己的信息注册上去;
- 其他 Kafka 节点会监听Zookeeper 的这些注册路径;
- 若某个 Kafka 节点挂了,它和 Zookeeper 的网络连接断开,对应的注册节点会自动消失,Zookeeper 会立刻把 “节点消失” 的消息通知给所有监听的节点;
- 收到通知的节点就知道集群有变化,进而触发后续操作(比如重新选 Leader、分配分区)。
Zookeeper 感知 Kafka 集群变化的核心,是用 “临时节点” 绑定 Kafka 组件的生命周期(组件活则节点在,组件死则节点删),用 “事件监听” 实现 “变化主动通知”—— 无需 Kafka 组件频繁查询 Zookeeper,而是由 Zookeeper 在变化发生时 “推消息”,从而实现高效、实时的集群状态感知。
升级后的Kraft,是怎么管理kafka的集群的?
Kraft 就是让 Kafka 自己的节点分工合作,用 Raft 算法保证 “领导组” 决策一致,靠内部直接通信替代 Zookeeper 的外部协调,从而更高效、更稳定。
首先在Kafka集群中,分为controller和broker两个角色,controller用于元数据管理和更新,其中包含主controller和从controller,主 Controller 是通过 Raft 协议从 Controller 节点组中选举产生的,且所有元数据变更(如创建 Topic、Leader 切换)必须经过主 Controller 处理,并同步到多数从 Controller 后才生效(Raft 的 “多数确认” 机制)。这保证了元数据的一致性,避免了单节点故障导致的决策混乱 。
broker负责消息的的存储和交互,他的元数据来源于controller,每个broker的元数据都会保持最终一致,无论是消费者还是生产者都会在消费消息或者生产消息的时候随机选取一个broker节点获取元数据然后读写消息。
另外消费者组的信息(如消费进度、分区分配)会作为元数据被 Controller 管理,通过注册信息以保证消费连续性。生产者仅作为 “消息发送者”,无需在集群中留下持久化信息。